1 Mysql中的索引
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。
1.1 MyISAM索引实现

MyISAM表的索引和数据是分离的,索引保存在”表名.MYI”文件内,而数据保存在“表名.MYD”文件内。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
1.2 InnoDB索引实现
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
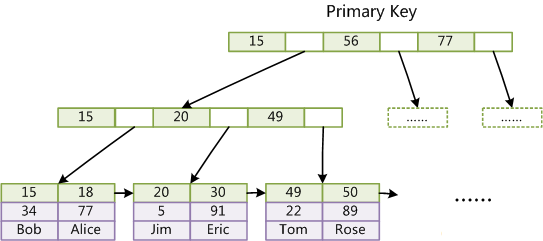
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
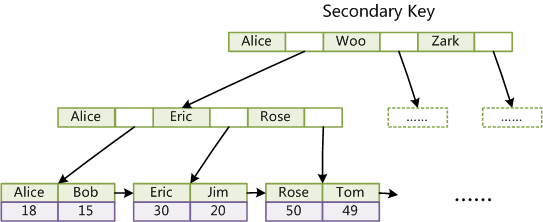
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
传统关系型数据库大部分采用B-Tree/B+Tree这样的数据结构。我们知道二叉树的查找效率是logN,同时写入更新新的节点不必移动全部节点,所以树型结构存储索引,能同时兼顾写入和查询性能。当我们不需要支持快速的更新的时候,则可以用预先排序等方式换取更小的存储空间,更快的检索速度等好处,其代价就是更新慢。
2 倒排索引
Elasticsearch使用一种称为倒排索引的结构,它适用于快速的全文搜索。
一个倒排索引由文档中所有不能重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
倒排索引包含:文档的列表、文档的数量、词条在每个文档中出现的次数、出现的位置、每个文档的长度、所有文档的平均长度。
索引不可变的原因:不需要锁,提升并发性能;可以一直保存在缓存中(filter,过滤查询可以体现,详情查看:Elasticsearch 过滤查询);节省cpu和io开销 。

一个例子:

ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name:

Age:

Sex:

Posting List:
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
看到这里,不要认为就结束了,精彩的部分才刚开始...
通过posting list这种索引方式似乎可以很快进行查找,比如要找age=24的同学,爱回答问题的小明马上就举手回答:我知道,id是1,2的同学。但是,如果这里有上千万的记录呢?如果是想通过name来查找呢?
Term Dictionary:
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index:
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
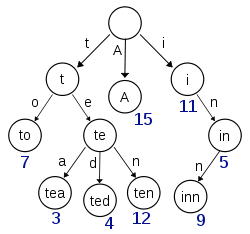
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
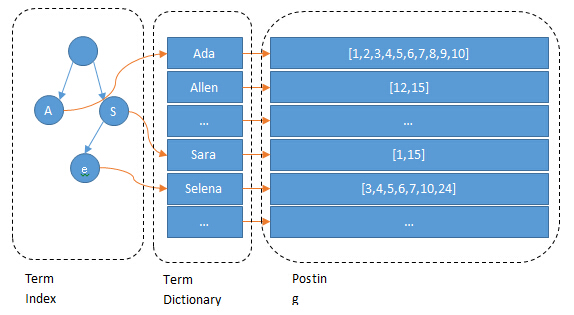
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
3 ElasticSearch对比关系型数据库
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{ "name" : "John", "sex" : "Male", "age" : 25, "birthDate": "1990/05/01", "about" : "I love to go rock climbing", "interests": [ "sports", "music" ]} 用Mysql这样的数据库存储就会容易想到建立一张User表,有6个字段等,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
| Relational DB | Databases | Tables | Rows | Columns |
|---|---|---|---|---|
| 关系型数据库 | 数据库 | 表 | 行 | 列 |
| Elasticsearch | Indices | Types | Documents | Fields |
|---|---|---|---|---|
| 搜索引擎 | 索引 | 类型 | 文档 | 域(字段) |
以上表格是一一对应的关系,比如上述代码块中的例子,对应到关系型数据库中就是1个数据库6个字段,对饮到ElasticSearch中就是1个索引,6种类型。
在Elasticsearch中,所有的字段缺省都建了索引。 也就是说每一个字段都有一个倒排索引,用于快速查询。
es支持http协议(json格式)(9200端口)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成),传统关系型数据库不支持。
es支持分片和复制,从而方便水平分割和扩展,复制保证了es的高可用与高吞吐。